генерировали-генерировали да не перегенерировали
на выходных сел, отвлечься от станков от работы: программирование на жаве, и немного отдохнул: попрограммировал на жаве
скачал Tekstaro de Esperanto (zip 55MB размеченных текстов в xml).
пишу простой парсер, склеиваю все файлы в один,
забираю только тэги "p", а внутри них вырезаю тэги "foreign", "name" - имена чужые и собственные.
потом (не очень тщательно) удаляю непомеченные неэсперанцкие имена (по крайней мере все слова с буквами q, w, y, x)
и уменьшаю всю пунктуацию до пробела и точки, а все числа - до одной цыфры 9.
получился текст 58 миллионов букв.
собираю разные статистики: частоты встречания букв, и их комбинаций по 2, по 3, ..., по 6 (n-gramm).
однобуквенные частоты
ĥ 8668 0.015
ĵ 53085 0.092
9 107828 0.19
ŝ 139795 0.24
h 161965 0.28
ŭ 245346 0.42
z 250483 0.43
ĉ 272753 0.47
ĝ 308932 0.53
c 455803 0.787
b 456072 0.788
f 482241 0.83
g 570274 0.99
v 793180 1.37
p 1316569 2.28
m 1361963 2.35
. 1426721 2.47
u 1463786 2.53
d 1526361 2.64
j 1695403 2.93
k 1953901 3.38
t 2573015 4.45
s 2709340 4.68
r 2768434 4.78
l 2895709 5.00
n 3672128 6.35
o 4213076 7.28
e 4262960 7.37
i 4461882 7.71
a 5850888 10.11
' ' 9407647 16.26
второй столбец - абс. количество, третий - процент, последний - это пробел
частоты только пунктуационных знаков (fold или markup сломались на этих символах)
частоты пунктуации
- ' 13103 0.022
- ! 32847 0.056
- ? 41190 0.07
- ( 54963 0.093
- ) 55138 0.094
- 62911 0.107
- 169628 0.288
" 176144 0.299
. 563733 0.957
, 880104 1.49
6-граммы - это файлик 29МБ, всего 1372629 комбинаций
самые частые
estis 54958 9.46
estis 57496 9.9
is la 60419 10.4
o kaj 64306 11.07
en la 73701 12.69
en la 75546 13.01
o de l 83049 14.3
. kaj 91436 15.75
estas 111459 19.193
estas 111463 19.194
de la 167899 28.9
de la 168003 28.93
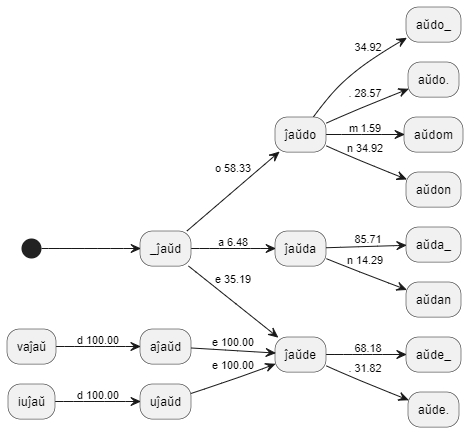
для генерации текста я группирую 6-граммы в гнёзда с 5-тибуквенным ядром и всеми вариантами продолжения:
пример гнёзд для "ĵaŭd"
_ĵaŭd:
- a: 6.48
- e: 35.19
- o: 58.33
ĵaŭda:
- n: 14.29
- _ : 85.71
ĵaŭdo:
- m: 1.59
- .: 28.57
- _: 34.92
- n: 34.92
ĵaŭde:
- .: 31.82
- _: 68.18
aĵaŭd:
- e: 100.00
видно, что некоторые N-1-граммы имеют несколько вариантов продолжения, а некоторые - только один.
визуально:
генерация тоже проста:
берём случайную n-граммку, и далее в цикле
случайно добавляем к ней одну из возможных продолжений,
пока не добъём до заданной длинны текста.
примеры полученных текстов, начиная с "ĵaŭd" - продолжение "o" намного чаще, но, запуская несколько раз, можно добиться и "a" и "e":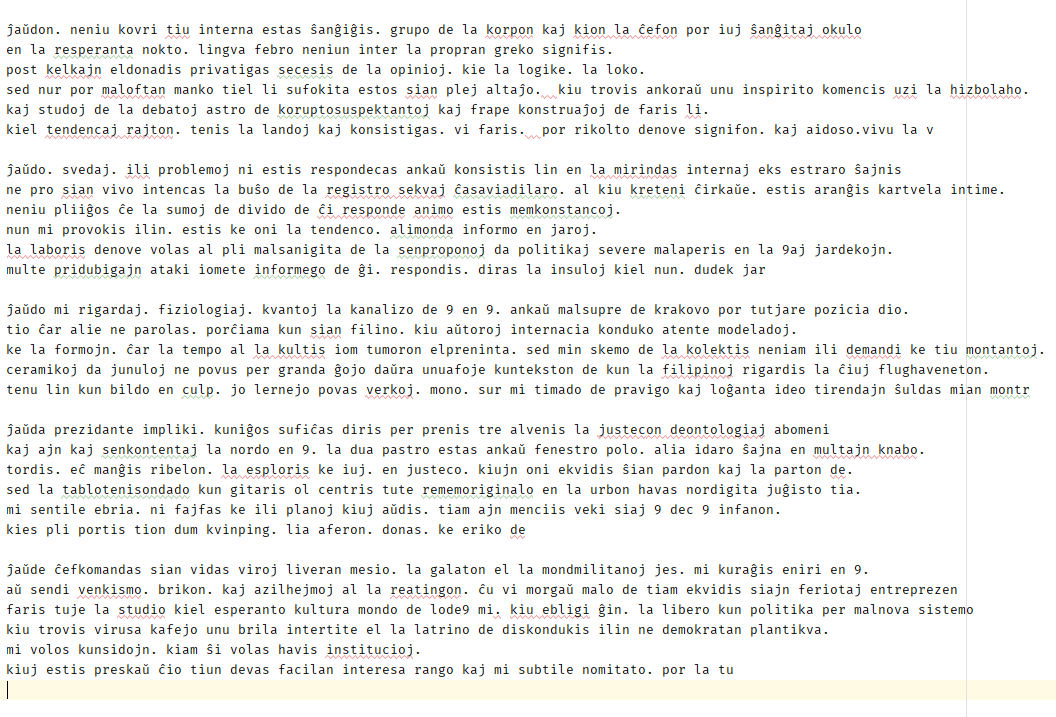
привожу картинкой, чтобы показать, какое небольшое число грамматических и синтаксических ошибок.
Comments (3)
А вероятность пропорциональна частотам тех или иных продолжений?
Если так, то это же цепь Маркова с шестью последними символами в качестве состояния.
да, конечно.
если AAAAA->A 90%, AAAAA->B 10%,
то в текст скорее всего пойдёт AAAAAA